
GPT-5.5 agentic AI - performances et prix de l’API
GPT-5.5 agentic AI arrive avec de meilleurs scores en agents et code, mais une API deux fois plus chère. Ce qu’il faut retenir sur performances et coûts.
OpenAI a lancé GPT-5.5 le 23 avril avec un positionnement clair - un modèle pensé pour le travail concret et pour alimenter des agents capables de planifier, d’utiliser des outils, de vérifier leurs sorties et d’avancer de façon plus autonome. L’objectif affiché est simple - réduire le besoin de multiples prompts et de corrections humaines en cours de route.
Dans cet article, on fait le point sur ce que change GPT-5.5 agentic AI en pratique - performances, benchmarks, efficacité en tokens et réalité tarifaire côté API.
Un modèle conçu pour les agents et l’exécution d’outils
GPT-5.5 est présenté comme le modèle agentique le plus capable d’OpenAI à ce jour. L’entreprise insiste sur une conception orientée exécution - planification, coordination d’outils, auto-vérification et progression sur des tâches complexes sans supervision constante.
C’est aussi le premier modèle de base réentraîné depuis GPT-4.5. OpenAI indique qu’il a été co-conçu avec les systèmes rack-scale NVIDIA GB200 et GB300 NVL72. En clair, la promesse n’est pas seulement une amélioration de “qualité de réponse”, mais une meilleure capacité à enchaîner des étapes et à terminer un travail avec moins d’allers-retours.
Le déploiement se fait dans ChatGPT et Codex pour les offres Plus, Pro, Business et Enterprise. L’accès API a suivi le 24 avril.
Benchmarks - où GPT-5.5 progresse nettement
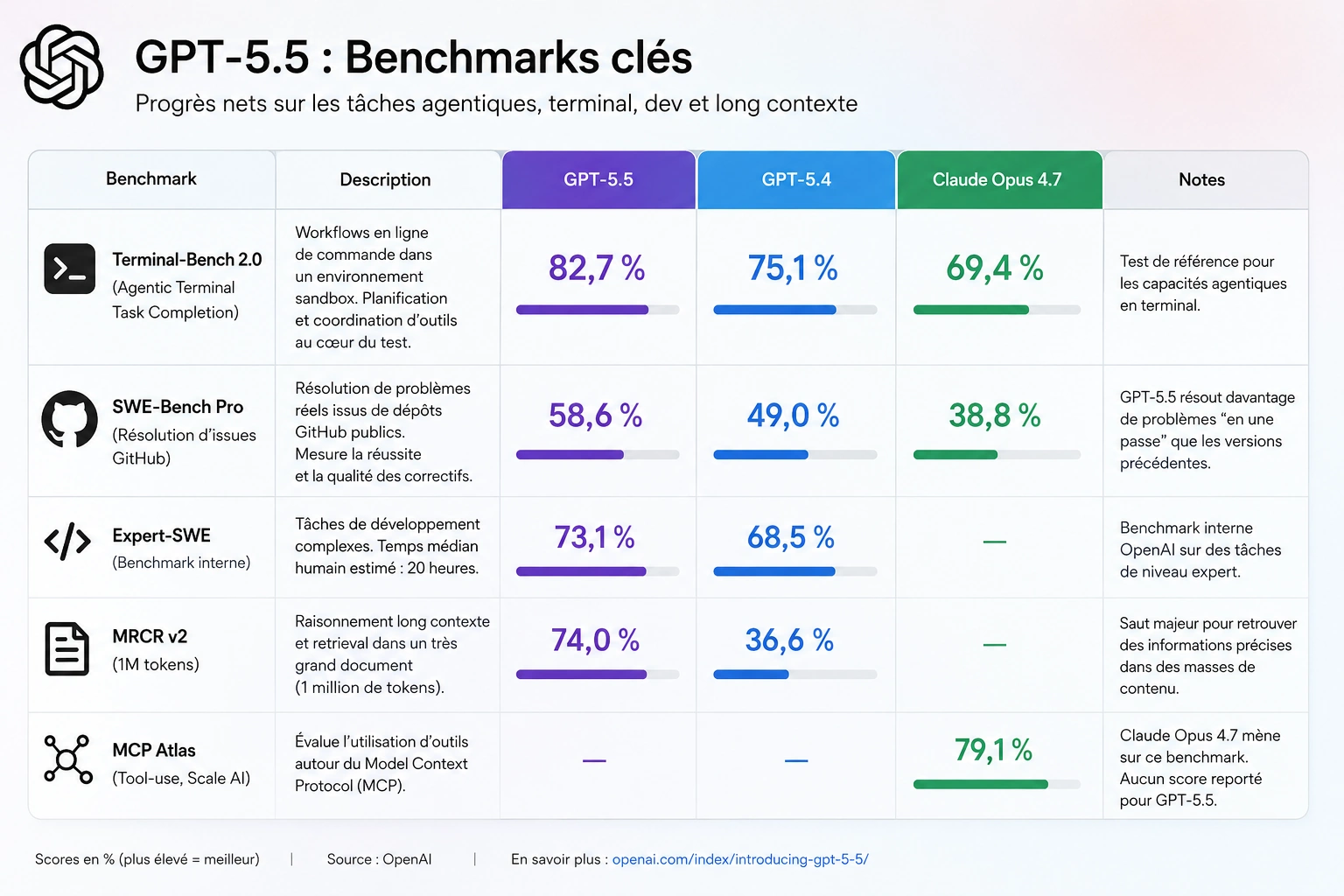
OpenAI met en avant plusieurs benchmarks orientés agents, terminal et résolution de tickets de développement.
Le signal le plus fort est Terminal-Bench 2.0, un test de workflows en ligne de commande dans un environnement sandbox, où la planification et la coordination d’outils sont centrales. GPT-5.5 atteint 82,7%, contre 75,1% pour GPT-5.4 et 69,4% pour Claude Opus 4.7.
Sur SWE-Bench Pro (résolution d’issues GitHub), GPT-5.5 monte à 58,6% et résout davantage de problèmes “en une passe” que les versions précédentes. OpenAI ajoute aussi Expert-SWE, un benchmark interne avec des tâches dont le temps médian humain estimé est de 20 heures - GPT-5.5 y obtient 73,1%, contre 68,5% pour GPT-5.4.
Enfin, sur le raisonnement long contexte, MRCR v2 à un million de tokens (retrieval dans un très grand document), GPT-5.5 affiche 74,0% contre 36,6% pour GPT-5.4. C’est un saut important, surtout pour des cas d’usage où l’agent doit retrouver une information précise noyée dans une masse de contenu.
Il reste toutefois un point à surveiller - sur MCP Atlas, le benchmark tool-use de Scale AI autour du Model Context Protocol, Claude Opus 4.7 mène à 79,1% et aucun score n’est reporté pour GPT-5.5. OpenAI a tout de même inclus cette absence dans son tableau, ce qui suggère qu’il assume la comparaison globale, mais cela peut compter pour les équipes très dépendantes d’une orchestration d’outils standardisée.
Pour en savoir plus sur l’annonce produit, la page officielle est disponible ici - https://openai.com/index/introducing-gpt-5-5/
Prix de l’API - x2 sur le papier, +20% selon OpenAI
Côté API, GPT-5.5 est facturé 5 dollars par million de tokens en entrée et 30 dollars par million de tokens en sortie. C’est exactement le double des tarifs de GPT-5.4.
La défense d’OpenAI est que GPT-5.5 consomme moins de tokens pour accomplir les mêmes tâches Codex que GPT-5.4. Une fois l’efficacité prise en compte, le surcoût effectif serait d’environ 20%. Cette affirmation a été validée par le laboratoire de tests indépendant Artificial Analysis.
OpenAI propose aussi GPT-5.5 Pro (pour Pro, Business et Enterprise), à 30 dollars par million de tokens en entrée et 180 dollars par million de tokens en sortie. Cette variante applique davantage de calcul parallèle au moment du test sur les problèmes difficiles. Elle arrive en tête de BrowseComp, le benchmark de navigation web agentique d’OpenAI, avec 90,1%.
Dans les faits, l’efficacité en tokens doit être testée sur vos workloads. Un exemple donné illustre bien l’enjeu - à 10 millions de tokens de sortie par mois, GPT-5.5 standard revient à 300 dollars contre 250 dollars pour Claude Opus 4.7, soit 20% d’écart. Cet écart ne “vaut le coup” que si les meilleures capacités agentiques réduisent réellement le nombre d’itérations, de relances et d’échecs - et ce calcul varie fortement selon les cas d’usage.
Ce que cela change en entreprise - Codex, automatisation et latence
OpenAI indique que plus de 85% de ses employés utilisent Codex chaque semaine, dans différents départements comme l’ingénierie et le marketing. Un exemple cité concerne l’équipe communication - GPT-5.5 a traité six mois de données de demandes de prise de parole et a construit un cadre de scoring et de gestion des risques pour automatiser les approbations à faible risque.
Sur le plan opérationnel, OpenAI affirme que GPT-5.5 conserve la même latence par token que GPT-5.4 en production, tout en offrant un niveau d’intelligence supérieur. C’est un point important - les modèles plus capables sont souvent plus lents à servir, et ici l’entreprise dit avoir évité ce compromis.
Reste la question clé pour les prochaines semaines - les gains observés en benchmark se traduiront-ils en gains mesurables dans des pipelines agentiques réels, avec des outils, des contraintes de sécurité, des environnements hétérogènes et des taux d’erreur qui coûtent cher ? Terminal-Bench est encourageant pour des agents “unattended” côté terminal, DevOps et automatisation. En parallèle, l’absence de score sur MCP Atlas mérite une vigilance particulière si votre architecture repose fortement sur l’orchestration d’outils via MCP.
Comment décider - quand passer à GPT-5.5
Avant de migrer, l’arbitrage se joue rarement sur un seul chiffre. Il faut confronter performance agentique, coût, stabilité et intégration outillée.
Voici 5 questions simples pour cadrer un test :
- Vos tâches exigent-elles de la planification multi-étapes et de l’exécution d’outils (terminal, web, dépôts git) ?
- Le coût principal vient-il des tokens de sortie, des relances, ou du temps humain de supervision ?
- Votre pipeline est-il sensible à la latence, ou plutôt au taux de réussite “du premier coup” ?
- Avez-vous des workloads long contexte où la recherche d’information dans de très grands documents est critique ?
- Votre stack dépend-elle fortement d’une orchestration MCP, et avez-vous une alternative si les résultats ne suivent pas ?
Conclusion
GPT-5.5 renforce clairement la proposition d’OpenAI sur l’IA agentique - meilleurs scores sur des benchmarks orientés terminal, progression sur la résolution d’issues et bond notable en retrieval long contexte. En contrepartie, l’API est deux fois plus chère sur le papier, avec un surcoût annoncé plus proche de 20% si l’efficacité en tokens se vérifie.
La décision de basculer vers GPT-5.5 agentic AI dépendra surtout de votre capacité à convertir ces gains en moins d’itérations, moins de supervision et un meilleur taux de réussite en production. Les benchmarks sont prometteurs, mais le verdict se jouera sur des tests en conditions réelles, au plus près de vos outils et de vos contraintes.